RapidMiner is an application provided for data analytics. We know that data analytics can be more complicated if you have to set the environment to run your project by yourself. You may need to learn a new programming language that you are not familiar with. In RapidMiner, it is helpful for data scientists to simulate the data more conveniently than it used to be. I search for algorithms that would be compatible with my data testing: Online Shoppers Purchasing Intention Dataset from UCI
There are many predictive models such as Random Tree, Decision Tree, Neural Network, and Navies Bayes.
The following list is a comparison of the models.
• Random tree is a collection of decision trees and the average/majority vote of the forest is selected as the predicted output.
• Random tree model will be less prone to overfitting than a Decision tree and gives a more generalized solution.
• Random tree is more robust and accurate than decision trees.
• Decision tree is a discriminative model, whereas Naive bayes is a generative model.
• Decision trees are more flexible and easier but they may neglect some key values in training data, which can lead to the accuracy of a toss.
• Decision trees are better when there is a large set of categorical values in training data.
• Decision trees are better than a neural network when the scenario demands an explanation of the decision.
• Neural network outperforms decision tree when there is sufficient training data.
• Neural Net Operator We can see the hidden layers and unproved by analytics as it is a computing system inspired by biological neural network
• Naive Bayes algorithm is a simple classification method. It is useful to create a very large number of attributes, and this algorithm works well with a large number of attributes. It can handle so many attributes quickly.
Naïve Bayes and Decision Tree to do advance analytics for this Online Shoppers Purchasing Intention Dataset UCI dataset since there are 18 attributes to evaluate which has a meaningful data on numerical variables and categorial variables
What is the predictive analysis objective(s), Why?
The online shopper dataset is a record from the e-commerce system to find out the factors that make customers decide to buy a product online and how customers interact on the e-commerce website which creates revenue for the company. The dataset measures customer engagement and any relevant before they make an order to purchase on an online website. To make a predictive analysis, the online dataset is an input to create a model. There are many algorithms to support data prediction and visualization for business. In our lecture, I choose two advanced analytics algorithms to classify this dataset.
What is your ETL process (sampling, veracity optimization) for predictive analytics?
Step 1: Find all attributes information to understand the purpose of this dataset.
Step 2: Think about the business question and what the outcome should be answered by this dataset. What do you want to know about this dataset? We try to find the factor that can create revenue when customers reach to the e-commerce website.
Step 3: Defined dependent(label) and independent variables(regular) in this dataset. In this simulation, Online Shoppers Purchasing Intention Dataset consists of 10 numerical and 8 categorical attributes. The ‘Revenue’ attribute can be used as the class label.
Step 4: Flittering data and setting the attribute role for the dataset. Some attributes may not always concern e.g. operating system, browser, etc.
Step 5: Set the sampling size to operate data that can gain the most accuracy for prediction. Step 6: Choose the right algorithm operation to experiment with the dataset which is most appropriate for its functional concept. I do experiment with this dataset by using Naïve Bayes and Decision Tree to do advance analytics.
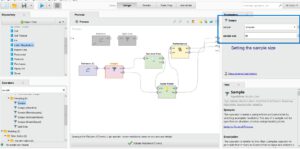
Set sample size as train and test data in RapidMinor
Step 7: Pass data from algorithm operation to Apply model operation
Step 8: Send all the data to the performance operation
Step 9: Summarized the result from the performance and choose the highest accuracy approach to analyze the dataset before doing the next recursion.
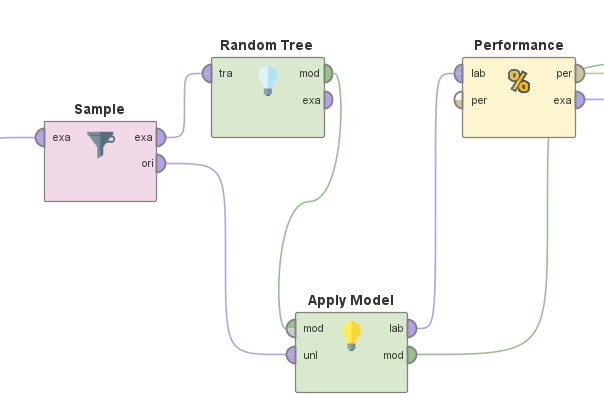
A Sample Classification Data in RapidMiner by Naive Bayes algorithms
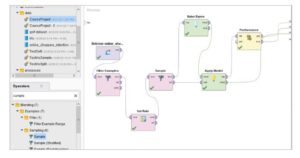
Naive Bayes – Composed all the components to analyze the data
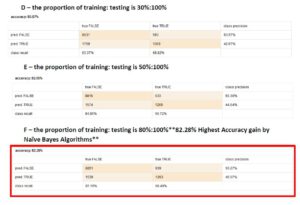
Naive Bayes – Performance accurate percentage of each sample size
A Sample Classification Data in RapidMiner by Decision Tree algorithms
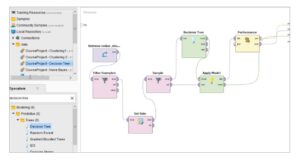
Decision Tree – Composed all the components to analyze the data

Decision Tree – Performance accurate percentage of each sample size
Comparison between Naïve Bayes and Decision Tree
Decision Tree is an outperforming approach to predicting online shopper intention datasets with the highest accuracy. In the experiment, setting a sampling size of 0.8 from a whole dataset gained the most accuracy 89.38%.
This blog is a part of my business intelligence course at Assumption University
Thank you to my advisor Dr. Kanoksak Wattanachote