Database transaction recovery and backup processes
-
NoSQL database transaction
To control a database transaction, we are well known in ACID properties which are required to apply in database operations. ACID transactions can guarantee a consistent state when a group of operations is running in the database, especially in a relational database system (RDBMS). For RDBMS, the data is predefined in a group of tables that have set a relationship with each other so that one transaction frequently requires data from two or more two tables. As we know, NoSQL database offers less schema to reduce the complexity to call the data in multi-layers. One of the most frequently cited drawbacks of NoSQL databases is that they don’t support ACID (atomicity, consistency, isolation, durability) transactions across multiple documents. With appropriate schema design, single-record atomicity is acceptable for lots of applications. However, there are still many applications that require ACID across multiple records. There are two most popular transaction models that we used in the database system as this following:
- The ACID model provides a consistent system.
- The BASE model provides high availability.
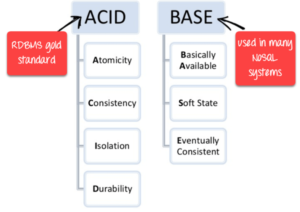
Difference between ACID vs BASE in DBMS
In this study, I will point out the BASE transaction model which is normally used in NoSQL since we learn a lot about ACID properties in a traditional database.
BASE transaction model is the transaction concept that generally uses in NoSQL databases since it provides a flexible and fluid way to manipulate data
BASE stands for:
- Basically Available – Rather than enforcing immediate consistency, BASE-modelled NoSQL databases will ensure the availability of data by spreading and replicating it across the nodes of the database cluster.
- Soft State – Due to the lack of immediate consistency, data values may change over time. The BASE model breaks off with the concept of a database that enforces its own consistency, delegating that responsibility to developers.
- Eventually Consistent – The fact that BASE does not enforce immediate consistency does not mean that it never achieves it. However, until it does, data reads are still possible (even though they might not reflect the reality).
In my reference, the expert makes the comparison between ACID and BASE transaction model to show how they use in the general use case.
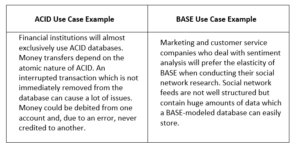
Regarding both use cases, I understand that BASE model enables easier scaling up and provides more flexibility. However, BASE also requires developers who will know how to deal with the limitations of the model.
Let’s get back to the popular NoSQL database system, MongoDB is a grateful NoSQL database product that can contain all the database management standards to support programmers. Storing the data in MongoDB would apply with a generic ACID property if there are two collections updating data simultaneously. For example, a customer who purchases 1 item will trick the order collection to update 1 record, and also update stock in the inventory collection at the same time.
MongoDB data model is more concerned with a transaction in a single document since research that 80-90% of MongoDB applications can handle a database in one defined collection. The programmer can store the data in a single document by using a variety of types, including subdocuments and arrays. The data does not fix the attribute and value like the predefined table in RDBMS composed of rows and columns. The figure is a sample JSON file that stores various data in a single-document.
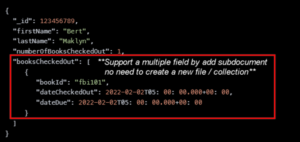
sample JSON file in MongoDB
However, it is necessary to handle all the database use cases in reality. Therefore, MongoDB has added support for multi-document ACID transactions and expanded the distributed transactions in the current version.
To pass the standard of a database transaction, it is important that MongoDB has to provide ACID transaction into a single document operation. In my opinion, MongoDB ACID transaction in a single document tends to support programming mechanisms more than functional usage in the application. On the other hand, MongoDB ACID transaction in a multi-document is the general usage in database management which is better to describe in general database use cases. I will give an example of ACID transaction in MongoDB between single and multi-document operations as this following table:
e.g., MongoDB performs “Atomicity”
- In a single document– A transaction with any data types must succeed or none of the operations should be committed.
- Across collections in a multi-document – Whenever an order is placed, the inventory collection needs to be updated to accurately reflect the number of copies remaining in stock. If an error occurs while updating the inventory or recording the order, the entire transaction should be aborted. Updating the inventory without recording the order or vice versa would leave the data in an inconsistent state.
e.g., MongoDB performs “Durability”
- In a single document– Once Single document operations in a transaction have been committed, MongoDB provides tunable write concernsthat ensure writes are not lost even in the event of an unexpected failure.
- Across collections in a multi-document – Consider an unexpected error like a database server crashing immediately after the database has confirmed that the transaction has been committed. The database should still have the updated inventory and order details from the committed transaction despite the unexpected server crash.
- NoSQL recovery and backup database
Database recovery and backup in DBMS are related to the transaction processing as it requests atomicity to determine the rollback state. Relational database or SQL database is the first database system that originally use DBMS concept to manipulate data in the system.
To recovery and backup files DBMS has defined these procedures to secure the data when a failure occurs in a database system as the following steps:
Step 1: Database is ARCHIVED periodically as backup on a hard disk
Step 2: Use the journal log file to record any transactions in the database
Step 3: When a failure occurs in a database system, the database manager can use ARCHIVE and LOG to REDO or UNDO back to a valid state.
This former recovery and backup processes are convenient for the administrator to maintain the database as the system provide the routine operations support such as automatically recording log file and operation command to roll back when a transaction or physical failure. As my study in assignment 1, I understand that SQL database has restrictions to the extent of the data capacity and is harder to config across the different systems which may cause by the administrative features (recovery and backup) default running in the database system. Moreover, the backup disk is reusable as set in the schedule to copy or remove the specific data at the appropriate time. At this time the backup disk price is lower than at the start era of SQL databases and more flexible to store in the cloud system. NoSQL database has the ability to backup and restores large data across multi-server which does not allow to do in the traditional database.
NoSQL databases do not apply all of the original database recovery and backup concepts from DBMS. Comparing the administrative part of SQL and NoSQL databases are designed with different mechanisms to execute the backup and recovery process when the database system detects the system is corrupted.
SQL database has two rollback state to move backward call UNDO or to move forward REDO the database depend on the failure types as shown in the figure.
- If the failure is caused by the transaction, the system will go to read the log file to UNDO for all activity before the failure.
- If the failure is caused form the hard disk crash, the system will go to read the log file to REDO the activity at the failure time.
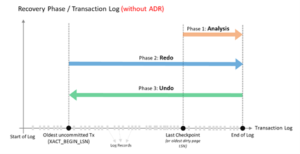
SQL database recovery chart
Assume that NoSQL database system can contain large data files and perform scalability as its architecture support so programmers can drop some part of data validation to backup and restore the data. In NoSQL database, the system requests to predefine two different states in a buffer against data loss. A backup and recovery plan is essential, being built around two core configurations as shown in the figure: Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
- RPO is defined by the age of data in backup storage needed to resume normal operations after a failure.
- RTO defines the time needed to restore the system to a normal state.
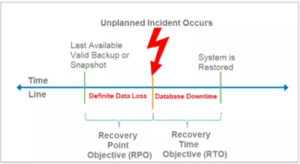
NoSQL database recovery chart
A classic database restore plan might include a single daily backup along with differential backups every hour to support a one-hour RPO. For a large database, the recovery time for a full restore can take hours to days, and every backup takes additional storage space.
- An Example of MongoDB backup and restore database
NoSQL database has various backup methods and restores data since we can implement any kind of source code and import other integrated tools to back up the data through this unstructured database. By the way, NoSQL database record the critical changes in a log file as same as the traditional approach. So that the programmer can estimate the damage circumstance when the system should be backed up and restored according to the transaction in the log file. NoSQL database does not provide the strong recovery and backup mode as SQL database. The flexible characteristic of NoSQL database leverages the programming application to provide other methods to prevent data loss such as cloud transferring backup, LVM physical backup, etc.
MongoDB enables users to back up and restore their databases. A database can be backed up and restored using either MongoDB backup and restore utilities or the cloud database platform MongoDB Atlas.
There are two types of backups in MongoDB: logical backups and physical backups.
- Logical backups dump data from databases into backup files, formatted as a BSON file. During the logical backup process, client APIs are used to get the data from the server. The data is encrypted, serialized, and written as either a “.bson,” “.json,” or “.csv” file, depending on the backup utility used.
MongoDB supplies two utilities to manage logical backups: Mongodump and Mongorestore.
- The Mongodump command dumps a backup of the database into the “.bson” format, and this can be restored by providing the logical statements found in the dump file to the databases.
- The Mongorestore command is used to restore the dump files created by Mongodump. Index creation happens after the data is restored.
- Physical backups are snapshots of the data files in MongoDB at a given point in time. The snapshots can be used to cleanly recover the database, as they include all the data found when the snapshot was created. Physical backups are critical when attempting to back up large databases quickly. Physical backups make copies of all the physical files that belong to a database, such as the data files, control files, and log files. The database files are saved onto a type of storage media, and they can then be used to restore a database system if there is damage to the system. We could use a physical backup snapshot alongside MongoDB Atlas to recover a lost or damaged database.
Concurrency Control and Isolation Levels
- Concurrency Control technique adopted in NoSQL database
DBMS systems are designed with concurrency control techniques to ensure correctness among operations that are executed simultaneously in a system. The purpose of database concurrency is to enable two or more users to retrieve information from the database at the same time without affecting data integrity.
In this study, I would like to know which concurrency technique is adopted in NoSQL database system. The research from I.J. Information Technology and Computer Science public in 2016, 12, 59-66 summarized in table 1
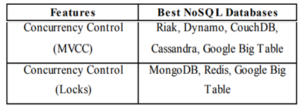
Table 1: NoSQL Databases mapped Concurrency Control technique
There are 2 types of concurrency database control techniques that are mostly applied in NoSQL database systems currently as this following:
- Lock-based protocols:In multi-user databases, require every transaction to request an appropriate lock before data read or write operations to prevent data integrity issues. A lock merely denotes the type of operations (read and write) permitted on a particular data object. Shared and exclusive locks are typically active to prevent data integrity problems during concurrent database transactions.
Example NoSQL database with Lock-based protocols:
MongoDB allows multiple clients to read and write the same data. To ensure consistency, MongoDB uses locking and concurrency control to prevent clients from modifying the same data simultaneously. Writes to a single document occur either in full or not at all, and clients always see consistent data. MongoDB uses multi-granularity locking in different levels and modes of locking to achieve the concurrency control
Locking levels: –
There are four different levels of locking in MongoDB.
- Global: It is a MongoDB instance-level lock where all the databases will be locked.
- Database: This is a database-level lock in which the mentioned database will be locked.
- Collection: Here the locking is handled at the collection level
- Document: It is a document-level locking where only that particular document will be locked.
Locking modes: –
Below are the various locking modes available.
- Shared (R)
The resource will be shared with concurrent readers.
This mode is used for the read operations
- Exclusive (W)
The resource will not be available for the other concurrent readers.
This mode is used for the writing operations
- Intent Shared (r)
Intent locks are higher-level locks acquired before lower-level locks.
It indicates that the lock holder will read the resource at a granular level. If Intent Shared (r) lock is applied to a database, then it means that the lock holder is willing to apply a Shared (S) lock on Collection or Document level.
- Intent Exclusive (w)
It indicates that the lock holder will modify the resource at a granular level. If Intent Exclusive (w) lock is applied to a database, then it means that the lock holder is willing to apply an Exclusive (X) lock on Collection or Document level.
- Multi-version concurrency control (MVCC) protocols: Databases like Oracle and Postgres utilize multi-version concurrency control to eliminate data consistency issues evident in simultaneous transactions. It helps eliminate the read-and-write operation conflicts arising during concurrent transactions. MVCC is typically used with other concurrency control mechanisms for better results, such as multi-version timestamp ordering and multi-version two-phase locking.
Example NoSQL database with MVCC protocols:
CouchDB uses Multi-Version Concurrency Control (MVCC) to manage concurrent access to the database. It uses append-only log files to eliminate the need for read locks in database transactions. MVCC allows multiple processes to read the same data concurrently by assigning a timestamp to the read data. Each process may then perform computations and, if necessary, write the data back to the database using the normal locking mechanism. Write operations proceed only if the timestamp held by the process matches the timestamp of the data to be overwritten, and they are made by creating an entirely new copy of the database that serves as the new current data snapshot. Older versions of the database remain logged in the system for reads by other processes during the copy operation as well as to maintain consistency in rebuilding the database in the event of a system crash during a write operation. MVCC thus eliminates read-locks and alleviates the database access bottleneck at the expense of additional memory requirements and more complicated failure recovery.
MVCC means that CouchDB can run at full speed, all the time, even under high loads. Requests are run in parallel, making excellent use of every last drop of processing power your server has to offer.
MVCC in CouchDB
- Isolation level in NoSQL database
Isolation determines how transaction integrity is visible to other users and systems. Isolation levels define the degree to which a transaction must be isolated from the data modifications made by any other transaction in the database system. As we know, there are four isolation levels defined in DBMS but they cannot use all in NoSQL database since it will miss the implementation of their use case. The data consistency in each isolation level is different. As shown in Table 2, only read un-committed accepted the dirty Read/Write into the database that is required to use in NoSQL database. The serializable isolation level is strongly used in the traditional database such as SQL server, and MySQL database to secure the data as the system guarantee ACID properties in every transaction. For instance, In SQL database, supposed that there should not be interrupted transactions during the bank account transfers.
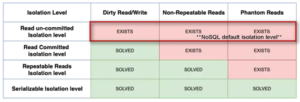
Table 2: Isolation level with identified data consistency- https://medium.com/geekculture/transaction-isolation-levels-f438f861e48a
In NoSQL database, the system needs to accept all transactions to support the application. Likely NoSQL databases aim to handle the online transaction processing that has to allow non-commit transactions into the database. In this study, I realize that read uncommitted is a default isolation level in most of the NoSQL databases such as MongoDB, CouchDB, Couchbase, etc.
Read Uncommitted Isolation Level in NoSQL database can be referred to by this definition – “This type of Isolation level is used when we want even the non-committed values of the rows. Any updates and inserts that are even not committed should be reflected in our transaction. This type of isolation level finds heavy use in the booking systems where if any other transaction is trying to update the availability of a seat, even though that transaction is not committed, we should be able to see those changes.” –https://levelup.gitconnected.com/understanding-isolation-levels-in-a-database-transaction
However, NoSQL database systems can customize the isolation level depending on the use case or programmer define configuration to identify the isolation level which is suitable for the application.
Query Processing and Optimization
We study the query processing first to find out the plan to do the optimization in the database system. In many organizations, they try to reduce the system resources required to fulfill a query and ultimately provide the user with the correct result set faster. All NoSQL vendors guarantees that the query process must be faster than the traditional database because NoSQL database has flexible data models, scale horizontally, have incredibly fast queries, and are easy for developers to work with. In this study, I find out that the way that they do the optimization in SQL and NoSQL databases is quite different. In SQL databases, we use the SQL phase to write or read the data from the database. From DBMS concept, the different order or command in the SQL phase may cause the query processing lower performance since it is related to the execution plan in the database. There are two main points that SQL databases used to optimize query processing as this following:
- Analyze and transform equivalent relational expressions: Try to minimize the tuple and column counts of the intermediate and final query processes (discussed here).
- Using different algorithms for each operation: These underlying algorithms determine how tuples are accessed from the data structures they are stored in, indexing, hashing, and data retrieval and hence influence the number of disk and block accesses (discussed in query processing).
SQL databases do the optimization by choosing the operation with the right algorithms that are mandatory configurations in the traditional database system. On the other hand, NoSQL databases may use a simple or complex technique to optimize the query processing depending on the need of use cases which are handled by programmers. As a result, I supposed that SQL databases would be easier to optimize the query processes rather than the NoSQL database. NoSQL feature is available for any programming mechanism which let the programmers decide by themselves. The article from a data scientist who has the experience to design the algorithm to optimize the query processing in NoSQL database has explored the query technique used to apply in the NoSQL project. There are two common techniques that would only support in NoSQL database system that can execute many required queries at the same time as this following:
- Scatter/Gather Local Search
Some of the NOSQL DB provide indexing and query processing mechanisms within the local DB. In this case, we can have the query processor broadcast the query to every node in the distributed hash table where a local search will be conducted with results sent back to the query processor which aggregates into a single response. Notice that the search is happening in parallel across all nodes in the DHT.
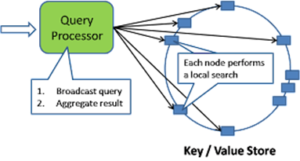
Query processing with scatter/gather local
- Prefix Hash Table (distributed Trie)
Trie is an alternative data structure, where every path (from the root) contains the prefix of the key. Basically, every node in the Trie contains all the data whose key is prefixed by it. Berkeley and Intel research has a paper to describe this mechanism.
Query processing with Prefix Hash Table
All in all, the study on BASE model in section 1 let me know that NoSQL database is designed to make data easy to access, and rarely to require joins or transactions. However, when we need to do complex querying, it’s more than up to the task. NoSQL query processes allow the programmer to query deep into any data type and even perform complex analytics pipelines with just a few lines of declarative code.
This blog is a part of my database course at Assumption University
Thank you to my advisor Prof. Dr. Suphamit Chittayasothorn.
Reference
https://www.mongodb.com/nosql-explained/nosql-vs-sql
https://www.guru99.com/sql-vs-nosql.html
https://www.mongodb.com/databases/types/transactional-databases
https://www.mongodb.com/basics/acid-transactions
https://www.mongodb.com/basics/backup-and-restore
https://www.geeksforgeeks.org/database-recovery-techniques-in-dbms/
https://www.scylladb.com/learn/nosql/sql-vs-nosql-database-administration/
https://www.guru99.com/dbms-concurrency-control.html
https://www.geeksforgeeks.org/transaction-isolation-levels-dbms/
https://www.mongodb.com/docs/manual/faq/concurrency/
https://phoenixnap.com/kb/acid-vs-base
https://www.solarwinds.com/resources/it-glossary/database-concurrency
https://www.mecs-press.org/ijitcs/ijitcs-v8-n12/IJITCS-V8-N12-7.pdf
https://sites.google.com/site/dbenginetestapp/mvcc-vs-locking/mvcc
https://www.javatpoint.com/query-processing-in-dbms
https://www.geeksforgeeks.org/query-optimization-in-relational-algebra/
https://dzone.com/articles/query-processing-nosql-db
https://www.couchbase.com/blog/query-optimization-in-nosql-couchbase-mongodb/